
.jpg)
PROTECT YOUR DNA WITH QUANTUM TECHNOLOGY
Orgo-Life the new way to the future Advertising by AdpathwayBERT is a foundational NLP model trained to understand language, but it may not work for any specific task out of the box. However, you can build upon BERT by adding appropriate model heads and training it for a specific task. This process is called fine-tuning. In this article, you will learn how to fine-tune a BERT model for several NLP tasks.
Let’s get started.
Overview
This article is divided into two parts; they are:
- Fine-tuning a BERT Model for GLUE Tasks
- Fine-tuning a BERT Model for SQuAD Tasks
Fine-tuning a BERT Model for GLUE Tasks
GLUE is a benchmark for evaluating natural language understanding (NLU) tasks. It contains 9 tasks, such as sentiment analysis, paraphrase identification, and text classification. The model learns task-specific behavior from examples. GLUE has a held-out test set to evaluate model performance on each task, with results reported on a public leaderboard.
Let’s take the “sst2” task (sentiment classification) in GLUE as an example.
You can load the dataset using the Hugging Face datasets library:
from datasets import load_dataset task = "sst2" # sentiment classification dataset = load_dataset("glue", task) print("Train size:", len(dataset["train"])) print("Validation size:", len(dataset["validation"])) print("Test size:", len(dataset["test"])) # print one sample print(dataset["train"][42]) |
Running this code, the output is:
Train size: 67349 Validation size: 872 Test size: 1821 {'sentence': "as they come , already having been recycled more times than i 'd care to count ", 'label': 0, 'idx': 42} |
The dataset loaded has three splits: train, validation, and test. Each sample in the dataset is a dictionary. The keys that we are interested in are "sentence" and "label". The label is either 0 or 1, representing negative or positive sentiment, respectively.
This dataset cannot be used directly because you need to convert text sentences into token sequences. Moreover, the training loop requires data in batches, so you need to create batches of shuffled and padded sequences. Let’s create a PyTorch DataLoader with a custom collate function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
... import torch def collate(batch: list[dict], tokenizer: tokenizers.Tokenizer, max_len: int): """Custom collate function to handle variable-length sequences in dataset.""" cls_id = tokenizer.token_to_id("[CLS]") sep_id = tokenizer.token_to_id("[SEP]") pad_id = tokenizer.token_to_id("[PAD]") sentences: list[str] = [item["sentence"] for item in batch] labels = torch.tensor([item["label"] for item in batch]) input_ids = [] for sentence in sentences: seq = [cls_id] seq.extend(tokenizer.encode(sentence).ids) if len(seq) >= max_len: seq = seq[:max_len-1] seq.append(sep_id) num_pad = max_len - len(seq) seq.extend([pad_id] * num_pad) input_ids.append(seq) input_ids = torch.tensor(input_ids, dtype=torch.long) return input_ids, labels batch_size = 16 max_len = 128 tokenizer = tokenizers.Tokenizer.from_file("wikitext-2_wordpiece.json") collate_fn = functools.partial(collate, tokenizer=tokenizer, max_len=max_len) train_loader = torch.utils.data.DataLoader(dataset["train"], batch_size=batch_size, shuffle=True, collate_fn=collate_fn) val_loader = torch.utils.data.DataLoader(dataset["validation"], batch_size=batch_size, shuffle=False, collate_fn=collate_fn) |
To prepare the data, you need to use the tokenizer that you trained in the previous post. The BERT model should also be trained with the same tokenizer.
The collate() function takes a batch of samples as a list of dictionaries. It converts text sentences into token sequences and pads them to the same length. Unlike BERT pre-training, you do not have a pair of sentences, but you still need to use the [CLS] and [SEP] tokens as delimiters in the output sequence. The output of the collate function is a tuple of two tensors: the input IDs as a 2D tensor and the labels as a 1D tensor.
You set up two DataLoader objects: one for the training set and one for the validation set. The training set is shuffled, but the validation set is not.
Next, you need to set up a model for GLUE tasks. Since this is a sentence classification task, you just need to add a linear layer on top of the BERT model to project the hidden state of the [CLS] token to the number of labels. Below is the implementation:
... class BertForSequenceClassification(nn.Module): """BERT model for GLUE tasks.""" def __init__(self, config: BertConfig, num_labels: int): super().__init__() self.bert = BertModel(config) self.classifier = nn.Linear(config.hidden_size, num_labels) def forward(self, input_ids: torch.Tensor, pad_id: int = 0) -> torch.Tensor: # pooled_output corresponds to the [CLS] token token_type_ids = torch.zeros_like(input_ids) seq_output, pooled_output = self.bert(input_ids, token_type_ids, pad_id=pad_id) logits = self.classifier(pooled_output) return logits |
You reuse the BertModel and BertConfig classes defined in the previous post. In the BertForSequenceClassification class, you use the foundation BERT model to process the input sequence. The pooled output, which corresponds to the [CLS] token, is then passed to a linear layer to project it to the number of labels. The sequence output, however, is unused. The model’s output is the logits for the classification task. In the case of sentiment classification, this is a vector of two values for each sample.
All fine-tuning of BERT model follows this similar architecture. In fact, you can see the figure below from the BERT paper that you are using the (b) architecture:
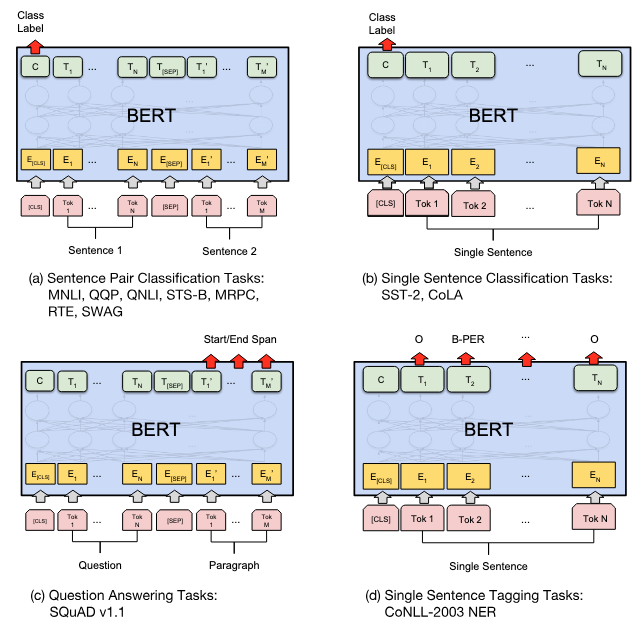
Different fine-tuning architecture of BERT. Figure from the BERT paper.
Since you have already trained the foundation BERT model, you can instantiate the model for sequence classification and then load the pretrained weights for the foundation model:
... device = torch.device("cuda" if torch.cuda.is_available() else "cpu") config = BertConfig() model = BertForSequenceClassification(config, num_labels) model.to(device) model.bert.load_state_dict(torch.load("bert_model.pth", map_location=device)) |
Now you can run the training loop. Compared to pre-training, fine-tuning only requires a few epochs. Otherwise, the training loop is quite typical:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
.. loss_fn = nn.CrossEntropyLoss() optimizer = optim.AdamW(model.parameters(), lr=2e-5) num_epochs = 3 for epoch in range(num_epochs): model.train() # Training with tqdm.tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}") as pbar: for batch in pbar: # get batched data input_ids, labels = batch input_ids = input_ids.to(device) labels = labels.to(device) # forward pass logits = model(input_ids, torch.zeros_like(input_ids)) # backward pass optimizer.zero_grad() loss = loss_fn(logits, labels) loss.backward() optimizer.step() # update progress bar pbar.set_postfix(loss=float(loss)) pbar.update(1) # Validation: Keep track of the average loss and accuracy model.eval() val_loss, num_matches, num_batches, num_samples = 0, 0, 0, 0 with torch.no_grad(): for batch in val_loader: # get batched data input_ids, labels = batch input_ids = input_ids.to(device) labels = labels.to(device) # forward pass on validation data logits = model(input_ids) # compute loss loss = loss_fn(logits, labels) val_loss += loss.item() num_batches += 1 # compute accuracy predictions = logits.argmax(dim=-1) num_matches += (predictions == labels).sum().item() num_samples += len(labels) avg_loss = val_loss / num_batches acc = num_matches / num_samples print(f"Validation {epoch+1}/{num_epochs}: acc {acc:.4f}, avg loss {avg_loss:.4f}") |
Running this code, you may see:
Epoch 1/3: 100%|██████████████████████████| 4210/4210 [02:14<00:00, 31.37it/s, loss=0.844] Validation 1/3: acc 0.5092, avg loss 0.7097 Epoch 2/3: 100%|██████████████████████████| 4210/4210 [02:13<00:00, 31.46it/s, loss=0.591] Validation 2/3: acc 0.5092, avg loss 0.7164 Epoch 3/3: 100%|██████████████████████████| 4210/4210 [02:13<00:00, 31.51it/s, loss=0.699] Validation 3/3: acc 0.5092, avg loss 0.6932 |
Since you have both training and validation sets, you train with the training set and then evaluate on the validation set. Be sure to use model.train() and model.eval() to set the model to training or evaluation mode, respectively, since your model uses dropout layers.
That’s all you need to do to fine-tune a BERT model for GLUE tasks. Below is the complete code for sequence classification:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 |
import dataclasses import functools import torch import torch.nn as nn import torch.optim as optim import tqdm from datasets import load_dataset from tokenizers import Tokenizer from torch import Tensor # BERT config and model defined previously @dataclasses.dataclass class BertConfig: """Configuration for BERT model.""" vocab_size: int = 30522 num_layers: int = 12 hidden_size: int = 768 num_heads: int = 12 dropout_prob: float = 0.1 pad_id: int = 0 max_seq_len: int = 512 num_types: int = 2 class BertBlock(nn.Module): """One transformer block in BERT.""" def __init__(self, hidden_size: int, num_heads: int, dropout_prob: float): super().__init__() self.attention = nn.MultiheadAttention(hidden_size, num_heads, dropout=dropout_prob, batch_first=True) self.attn_norm = nn.LayerNorm(hidden_size) self.ff_norm = nn.LayerNorm(hidden_size) self.dropout = nn.Dropout(dropout_prob) self.feed_forward = nn.Sequential( nn.Linear(hidden_size, 4 * hidden_size), nn.GELU(), nn.Linear(4 * hidden_size, hidden_size), ) def forward(self, x: Tensor, pad_mask: Tensor) -> Tensor: # self-attention with padding mask and post-norm attn_output, _ = self.attention(x, x, x, key_padding_mask=pad_mask) x = self.attn_norm(x + attn_output) # feed-forward with GeLU activation and post-norm ff_output = self.feed_forward(x) x = self.ff_norm(x + self.dropout(ff_output)) return x class BertPooler(nn.Module): """Pooler layer for BERT to process the [CLS] token output.""" def __init__(self, hidden_size: int): super().__init__() self.dense = nn.Linear(hidden_size, hidden_size) self.activation = nn.Tanh() def forward(self, x: Tensor) -> Tensor: x = self.dense(x) x = self.activation(x) return x class BertModel(nn.Module): """Backbone of BERT model.""" def __init__(self, config: BertConfig): super().__init__() # embedding layers self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_id) self.type_embeddings = nn.Embedding(config.num_types, config.hidden_size) self.position_embeddings = nn.Embedding(config.max_seq_len, config.hidden_size) self.embeddings_norm = nn.LayerNorm(config.hidden_size) self.embeddings_dropout = nn.Dropout(config.dropout_prob) # transformer blocks self.blocks = nn.ModuleList([ BertBlock(config.hidden_size, config.num_heads, config.dropout_prob) for _ in range(config.num_layers) ]) # [CLS] pooler layer self.pooler = BertPooler(config.hidden_size) def forward(self, input_ids: Tensor, token_type_ids: Tensor, pad_id: int = 0, ) -> tuple[Tensor, Tensor]: # create attention mask for padding tokens pad_mask = input_ids == pad_id # convert integer tokens to embedding vectors batch_size, seq_len = input_ids.shape position_ids = torch.arange(seq_len, device=input_ids.device).unsqueeze(0) position_embeddings = self.position_embeddings(position_ids) type_embeddings = self.type_embeddings(token_type_ids) token_embeddings = self.word_embeddings(input_ids) x = token_embeddings + type_embeddings + position_embeddings x = self.embeddings_norm(x) x = self.embeddings_dropout(x) # process the sequence with transformer blocks for block in self.blocks: x = block(x, pad_mask) # pool the hidden state of the `[CLS]` token pooled_output = self.pooler(x[:, 0, :]) return x, pooled_output # Define new BERT model for sequence classification class BertForSequenceClassification(nn.Module): """BERT model for GLUE tasks.""" def __init__(self, config: BertConfig, num_labels: int): super().__init__() self.bert = BertModel(config) self.classifier = nn.Linear(config.hidden_size, num_labels) def forward(self, input_ids: Tensor, pad_id: int = 0) -> Tensor: # pooled_output corresponds to the [CLS] token token_type_ids = torch.zeros_like(input_ids) seq_output, pooled_output = self.bert(input_ids, token_type_ids, pad_id=pad_id) logits = self.classifier(pooled_output) return logits # Load GLUE dataset (e.g., 'sst2' for sentiment classification) task = "sst2" dataset = load_dataset("glue", task) num_labels = 2 # dataset["train"]["label"] is either 0 or 1 # Load the pretrained BERT tokenizer TOKENIZER_PATH = "wikitext-2_wordpiece.json" tokenizer = Tokenizer.from_file(TOKENIZER_PATH) # Setup dataloader for training and validation datasets def collate(batch: list[dict], tokenizer: Tokenizer, max_len: int) -> tuple[Tensor, Tensor]: """Collate variable-length sequences in the dataset.""" cls_id = tokenizer.token_to_id("[CLS]") sep_id = tokenizer.token_to_id("[SEP]") pad_id = tokenizer.token_to_id("[PAD]") sentences: list[str] = [item["sentence"] for item in batch] labels = torch.tensor([item["label"] for item in batch]) input_ids = [] for sentence in sentences: seq = [cls_id] seq.extend(tokenizer.encode(sentence).ids) if len(seq) >= max_len: seq = seq[:max_len-1] seq.append(sep_id) num_pad = max_len - len(seq) seq.extend([pad_id] * num_pad) input_ids.append(seq) input_ids = torch.tensor(input_ids, dtype=torch.long) return input_ids, labels batch_size = 16 max_len = 128 collate_fn = functools.partial(collate, tokenizer=tokenizer, max_len=max_len) train_loader = torch.utils.data.DataLoader(dataset["train"], batch_size=batch_size, shuffle=True, collate_fn=collate_fn) val_loader = torch.utils.data.DataLoader(dataset["validation"], batch_size=batch_size, shuffle=False, collate_fn=collate_fn) # Create classification model with a pretrained foundation BERT model device = torch.device("cuda" if torch.cuda.is_available() else "cpu") config = BertConfig() model = BertForSequenceClassification(config, num_labels) model.to(device) model.bert.load_state_dict(torch.load("bert_model.pth", map_location=device)) # Training setup loss_fn = nn.CrossEntropyLoss() optimizer = optim.AdamW(model.parameters(), lr=2e-5) num_epochs = 3 for epoch in range(num_epochs): model.train() # Training with tqdm.tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}") as pbar: for batch in pbar: # get batched data input_ids, labels = batch input_ids = input_ids.to(device) labels = labels.to(device) # forward pass logits = model(input_ids, torch.zeros_like(input_ids)) # backward pass optimizer.zero_grad() loss = loss_fn(logits, labels) loss.backward() optimizer.step() # update progress bar pbar.set_postfix(loss=float(loss)) pbar.update(1) # Validation: Keep track of the average loss and accuracy model.eval() val_loss, num_matches, num_batches, num_samples = 0, 0, 0, 0 with torch.no_grad(): for batch in val_loader: # get batched data input_ids, labels = batch input_ids = input_ids.to(device) labels = labels.to(device) # forward pass on validation data logits = model(input_ids) # compute loss loss = loss_fn(logits, labels) val_loss += loss.item() num_batches += 1 # compute accuracy predictions = logits.argmax(dim=-1) num_matches += (predictions == labels).sum().item() num_samples += len(labels) avg_loss = val_loss / num_batches acc = num_matches / num_samples print(f"Validation {epoch+1}/{num_epochs}: acc {acc:.4f}, avg loss {avg_loss:.4f}") # Save the fine-tuned model torch.save(model.state_dict(), f"bert_model_glue_sst2.pth") |
Fine-tuning a BERT Model for SQuAD
SQuAD is a question answering dataset. Each sample contains a question and a context paragraph. The answer to the question is a span of words within the context paragraph. This is not a general question answering task since the answer is always a substring in the context. If no such substring exists, the question has no answer.
Let’s take a look at one sample in the dataset:
from datasets import load_dataset dataset = load_dataset("squad") print("Train size:", len(dataset["train"])) print("Validation size:", len(dataset["validation"])) # print one sample print(dataset["train"][42]) |
Running this code, the output is:
Train size: 87599 Validation size: 10570 {'id': '5733ae924776f41900661016', 'title': 'University_of_Notre_Dame', 'context': 'Notre Dame is known for its competitive admissions, ...', 'question': 'What percentage of students at Notre Dame participated in the Early Action program?', 'answers': {'text': ['39.1%'], 'answer_start': [488]}} |
The SQuAD dataset has only training and validation splits. Each sample is a dictionary with the keys "id", "title", "context", "question", and "answers". The "answers" key is a dictionary containing the answer text and its offset in the context.
To train a model, you need to batch and process the data samples into tensors as you did for the GLUE tasks. Let’s create a custom collate function for the SQuAD dataset:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
... def collate(batch: list[dict], tokenizer: tokenizers.Tokenizer, max_len: int): cls_id = tokenizer.token_to_id("[CLS]") sep_id = tokenizer.token_to_id("[SEP]") pad_id = tokenizer.token_to_id("[PAD]") input_ids_list = [] token_type_ids_list = [] start_positions = [] end_positions = [] for item in batch: # Tokenize question and context question, context = item["question"], item["context"] question_ids = tokenizer.encode(question).ids context_ids = tokenizer.encode(context).ids # Build input: [CLS] question [SEP] context [SEP] input_ids = [cls_id, *question_ids, sep_id, *context_ids, sep_id] token_type_ids = [0] * (len(question_ids)+2) + [1] * (len(context_ids)+1) # Truncate or pad to max length if len(input_ids) > max_len: input_ids = input_ids[:max_len] token_type_ids = token_type_ids[:max_len] else: input_ids.extend([pad_id] * (max_len - len(input_ids))) token_type_ids.extend([1] * (max_len - len(token_type_ids))) # Find answer position in tokens: Answer may not be in the context start_pos = end_pos = 0 if len(item["answers"]["text"]) > 0: answers = tokenizer.encode(item["answers"]["text"][0]).ids # find the context offset of the answer in context_ids for i in range(len(context_ids) - len(answers) + 1): if context_ids[i:i+len(answers)] == answers: start_pos = i + len(question_ids) + 2 end_pos = start_pos + len(answers) - 1 break if end_pos >= max_len: start_pos = end_pos = 0 # answer is clipped, hence no answer input_ids_list.append(input_ids) token_type_ids_list.append(token_type_ids) start_positions.append(start_pos) end_positions.append(end_pos) input_ids_list = torch.tensor(input_ids_list) token_type_ids_list = torch.tensor(token_type_ids_list) start_positions = torch.tensor(start_positions) end_positions = torch.tensor(end_positions) return (input_ids_list, token_type_ids_list, start_positions, end_positions) batch_size = 16 max_len = 384 # Longer for Q&A to accommodate context collate_fn = functools.partial(collate, tokenizer=tokenizer, max_len=max_len) train_loader = torch.utils.data.DataLoader(dataset["train"], batch_size=batch_size, shuffle=True, collate_fn=collate_fn) val_loader = torch.utils.data.DataLoader(dataset["validation"], batch_size=batch_size, shuffle=False, collate_fn=collate_fn) |
This collate function is more complex than the one for GLUE tasks because you need to pass a pair of sentences as input in the format [CLS] question [SEP] context [SEP]. The context may be clipped to fit the maximum length. The question, context, and answer are all converted into token sequences. In the inner for-loop, you find the position of the answer span in the context. If the answer is not found within the provided context, you mark the question as having no answer.
One of the most important roles of the collate function is to create tensors for the whole batch. Here you produce four tensors: the input (including both question and context), the token type IDs (denoting which tokens belong to the question and which belong to the context), and the start and end positions of the answer span.
Next, you need to set up a model for SQuAD tasks. The strategy is to process the sequence output from the BERT model such that each token is transformed into a probability of being the start or end of the answer span. You can then look for the highest probability start and end tokens to form the answer span. The implementation is straightforward:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
... class BertForQuestionAnswering(nn.Module): """BERT model for SQuAD question answering.""" def __init__(self, config): super().__init__() self.bert = BertModel(config) # Two outputs: start and end position logits self.qa_outputs = nn.Linear(config.hidden_size, 2) def forward(self, input_ids, token_type_ids, pad_id: int = 0): # Get sequence output from BERT (batch_size, seq_len, hidden_size) seq_output, pooled_output = self.bert(input_ids, token_type_ids, pad_id=pad_id) # Project to start and end logits logits = self.qa_outputs(seq_output) # (batch_size, seq_len, 2) start_logits = logits[:, :, 0] # (batch_size, seq_len) end_logits = logits[:, :, 1] # (batch_size, seq_len) return start_logits, end_logits |
The foundation BERT model produces both sequence output and pooled output. You use only the sequence output for SQuAD tasks. You process the output through a linear layer to produce the start and end position logits and return them separately. To convert them to probabilities, you should apply the softmax function to the logits, which can be done outside the model. This model for fine-tuning follows the architecture (c) in the figure of the previous section.
As in the example for GLUE tasks above, you can instantiate the model and load the pretrained weights:
... device = torch.device("cuda" if torch.cuda.is_available() else "cpu") config = BertConfig() model = BertForQuestionAnswering(config) model.to(device) model.bert.load_state_dict(torch.load("bert_model.pth", map_location=device)) |
And finally, you can run the training loop for fine-tuning:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
.. loss_fn = nn.CrossEntropyLoss() optimizer = optim.AdamW(model.parameters(), lr=2e-5) num_epochs = 3 for epoch in range(num_epochs): model.train() # Training with tqdm.tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}") as pbar: for batch in pbar: # get batched data input_ids, token_type_ids, start_positions, end_positions = batch input_ids = input_ids.to(device) token_type_ids = token_type_ids.to(device) start_positions = start_positions.to(device) end_positions = end_positions.to(device) # forward pass start_logits, end_logits = model(input_ids, token_type_ids) # backward pass optimizer.zero_grad() start_loss = loss_fn(start_logits, start_positions) end_loss = loss_fn(end_logits, end_positions) loss = start_loss + end_loss loss.backward() optimizer.step() # update progress bar pbar.set_postfix(loss=float(loss)) pbar.update(1) # Validation: Keep track of the average loss and accuracy model.eval() val_loss, num_matches, num_batches, num_samples = 0, 0, 0, 0 with torch.no_grad(): for batch in val_loader: # get batched data input_ids, token_type_ids, start_positions, end_positions = batch input_ids = input_ids.to(device) token_type_ids = token_type_ids.to(device) start_positions = start_positions.to(device) end_positions = end_positions.to(device) # forward pass on validation data start_logits, end_logits = model(input_ids, token_type_ids) # compute loss start_loss = loss_fn(start_logits, start_positions) end_loss = loss_fn(end_logits, end_positions) loss = start_loss + end_loss val_loss += loss.item() num_batches += 1 # compute accuracy pred_start = start_logits.argmax(dim=-1) pred_end = end_logits.argmax(dim=-1) match = (pred_start == start_positions) & (pred_end == end_positions) num_matches += match.sum().item() num_samples += len(start_positions) avg_loss = val_loss / num_batches acc = num_matches / num_samples print(f"Validation {epoch+1}/{num_epochs}: acc {acc:.4f}, avg loss {avg_loss:.4f}") |
The training loop is similar to the one for GLUE tasks. Instead of using the pooled output, you now use the output corresponding to each token in the sequence. The token with the highest logit value is the predicted start or end position. The loss function is the sum of the cross-entropy losses for the predicted start and end positions.
This is a simplified way to use the model’s output. You can refine the logic by finding the start-end pair with the highest combined score under the constraint that the end position is greater than or equal to the start position. This may improve the model’s performance.
Running this code, you may see:
Epoch 1/3: 100%|████████████████████████████| 5475/5475 [07:45<00:00, 11.77it/s, loss=9.7] Validation 1/3: acc 0.0189, avg loss 8.6972 Epoch 2/3: 100%|███████████████████████████| 5475/5475 [07:44<00:00, 11.78it/s, loss=8.37] Validation 2/3: acc 0.0358, avg loss 8.2596 Epoch 3/3: 100%|███████████████████████████| 5475/5475 [07:44<00:00, 11.78it/s, loss=7.85] Validation 3/3: acc 0.0449, avg loss 7.9882 |
You may notice that the model’s performance is not very good. This is likely because the foundation BERT model was trained on the smaller WikiText-2 dataset, which does not generalize well to more complex tasks. For better performance in practical applications, you should use the official pretrained weights instead.
Below is the complete code for fine-tuning a BERT model for SQuAD tasks:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 |
import collections import dataclasses import functools import torch import torch.nn as nn import torch.optim as optim import tqdm from datasets import load_dataset from tokenizers import Tokenizer from torch import Tensor # BERT config and model defined previously @dataclasses.dataclass class BertConfig: """Configuration for BERT model.""" vocab_size: int = 30522 num_layers: int = 12 hidden_size: int = 768 num_heads: int = 12 dropout_prob: float = 0.1 pad_id: int = 0 max_seq_len: int = 512 num_types: int = 2 class BertBlock(nn.Module): """One transformer block in BERT.""" def __init__(self, hidden_size: int, num_heads: int, dropout_prob: float): super().__init__() self.attention = nn.MultiheadAttention(hidden_size, num_heads, dropout=dropout_prob, batch_first=True) self.attn_norm = nn.LayerNorm(hidden_size) self.ff_norm = nn.LayerNorm(hidden_size) self.dropout = nn.Dropout(dropout_prob) self.feed_forward = nn.Sequential( nn.Linear(hidden_size, 4 * hidden_size), nn.GELU(), nn.Linear(4 * hidden_size, hidden_size), ) def forward(self, x: Tensor, pad_mask: Tensor) -> Tensor: # self-attention with padding mask and post-norm attn_output, _ = self.attention(x, x, x, key_padding_mask=pad_mask) x = self.attn_norm(x + attn_output) # feed-forward with GeLU activation and post-norm ff_output = self.feed_forward(x) x = self.ff_norm(x + self.dropout(ff_output)) return x class BertPooler(nn.Module): """Pooler layer for BERT to process the [CLS] token output.""" def __init__(self, hidden_size: int): super().__init__() self.dense = nn.Linear(hidden_size, hidden_size) self.activation = nn.Tanh() def forward(self, x: Tensor) -> Tensor: x = self.dense(x) x = self.activation(x) return x class BertModel(nn.Module): """Backbone of BERT model.""" def __init__(self, config: BertConfig): super().__init__() # embedding layers self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_id) self.type_embeddings = nn.Embedding(config.num_types, config.hidden_size) self.position_embeddings = nn.Embedding(config.max_seq_len, config.hidden_size) self.embeddings_norm = nn.LayerNorm(config.hidden_size) self.embeddings_dropout = nn.Dropout(config.dropout_prob) # transformer blocks self.blocks = nn.ModuleList([ BertBlock(config.hidden_size, config.num_heads, config.dropout_prob) for _ in range(config.num_layers) ]) # [CLS] pooler layer self.pooler = BertPooler(config.hidden_size) def forward(self, input_ids: Tensor, token_type_ids: Tensor, pad_id: int = 0, ) -> tuple[Tensor, Tensor]: # create attention mask for padding tokens pad_mask = input_ids == pad_id # convert integer tokens to embedding vectors batch_size, seq_len = input_ids.shape position_ids = torch.arange(seq_len, device=input_ids.device).unsqueeze(0) position_embeddings = self.position_embeddings(position_ids) type_embeddings = self.type_embeddings(token_type_ids) token_embeddings = self.word_embeddings(input_ids) x = token_embeddings + type_embeddings + position_embeddings x = self.embeddings_norm(x) x = self.embeddings_dropout(x) # process the sequence with transformer blocks for block in self.blocks: x = block(x, pad_mask) # pool the hidden state of the `[CLS]` token pooled_output = self.pooler(x[:, 0, :]) return x, pooled_output # Define new BERT model for question answering class BertForQuestionAnswering(nn.Module): """BERT model for SQuAD question answering.""" def __init__(self, config: BertConfig): super().__init__() self.bert = BertModel(config) # Two outputs: start and end position logits self.qa_outputs = nn.Linear(config.hidden_size, 2) def forward(self, input_ids: Tensor, token_type_ids: Tensor, pad_id: int = 0, ) -> tuple[Tensor, Tensor]: # Get sequence output from BERT (batch_size, seq_len, hidden_size) seq_output, pooled_output = self.bert(input_ids, token_type_ids, pad_id=pad_id) # Project to start and end logits logits = self.qa_outputs(seq_output) # (batch_size, seq_len, 2) start_logits = logits[:, :, 0] # (batch_size, seq_len) end_logits = logits[:, :, 1] # (batch_size, seq_len) return start_logits, end_logits # Load SQuAD dataset for question answering dataset = load_dataset("squad") # Load the pretrained BERT tokenizer TOKENIZER_PATH = "wikitext-2_wordpiece.json" tokenizer = Tokenizer.from_file(TOKENIZER_PATH) # Setup collate function to tokenize question-context pairs for the model def collate(batch: list[dict], tokenizer: Tokenizer, max_len: int, ) -> tuple[Tensor, Tensor, Tensor, Tensor]: """Collate question-context pairs for the model.""" cls_id = tokenizer.token_to_id("[CLS]") sep_id = tokenizer.token_to_id("[SEP]") pad_id = tokenizer.token_to_id("[PAD]") input_ids_list = [] token_type_ids_list = [] start_positions = [] end_positions = [] for item in batch: # Tokenize question and context question, context = item["question"], item["context"] question_ids = tokenizer.encode(question).ids context_ids = tokenizer.encode(context).ids # Build input: [CLS] question [SEP] context [SEP] input_ids = [cls_id, *question_ids, sep_id, *context_ids, sep_id] token_type_ids = [0] * (len(question_ids)+2) + [1] * (len(context_ids)+1) # Truncate or pad to max length if len(input_ids) > max_len: input_ids = input_ids[:max_len] token_type_ids = token_type_ids[:max_len] else: input_ids.extend([pad_id] * (max_len - len(input_ids))) token_type_ids.extend([1] * (max_len - len(token_type_ids))) # Find answer position in tokens: Answer may not be in the context start_pos = end_pos = 0 if len(item["answers"]["text"]) > 0: answers = tokenizer.encode(item["answers"]["text"][0]).ids # find the context offset of the answer in context_ids for i in range(len(context_ids) - len(answers) + 1): if context_ids[i:i+len(answers)] == answers: start_pos = i + len(question_ids) + 2 end_pos = start_pos + len(answers) - 1 break if end_pos >= max_len: start_pos = end_pos = 0 # answer is clipped, hence no answer input_ids_list.append(input_ids) token_type_ids_list.append(token_type_ids) start_positions.append(start_pos) end_positions.append(end_pos) input_ids_list = torch.tensor(input_ids_list) token_type_ids_list = torch.tensor(token_type_ids_list) start_positions = torch.tensor(start_positions) end_positions = torch.tensor(end_positions) return (input_ids_list, token_type_ids_list, start_positions, end_positions) batch_size = 16 max_len = 384 # Longer for Q&A to accommodate context collate_fn = functools.partial(collate, tokenizer=tokenizer, max_len=max_len) train_loader = torch.utils.data.DataLoader(dataset["train"], batch_size=batch_size, shuffle=True, collate_fn=collate_fn) val_loader = torch.utils.data.DataLoader(dataset["validation"], batch_size=batch_size, shuffle=False, collate_fn=collate_fn) # Create Q&A model with a pretrained foundation BERT model device = torch.device("cuda" if torch.cuda.is_available() else "cpu") config = BertConfig() model = BertForQuestionAnswering(config) model.to(device) model.bert.load_state_dict(torch.load("bert_model.pth", map_location=device)) # Training setup loss_fn = nn.CrossEntropyLoss() optimizer = optim.AdamW(model.parameters(), lr=2e-5) num_epochs = 3 for epoch in range(num_epochs): model.train() # Training with tqdm.tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}") as pbar: for batch in pbar: # get batched data input_ids, token_type_ids, start_positions, end_positions = batch input_ids = input_ids.to(device) token_type_ids = token_type_ids.to(device) start_positions = start_positions.to(device) end_positions = end_positions.to(device) # forward pass start_logits, end_logits = model(input_ids, token_type_ids) # backward pass optimizer.zero_grad() start_loss = loss_fn(start_logits, start_positions) end_loss = loss_fn(end_logits, end_positions) loss = start_loss + end_loss loss.backward() optimizer.step() # update progress bar pbar.set_postfix(loss=float(loss)) pbar.update(1) # Validation: Keep track of the average loss and accuracy model.eval() val_loss, num_matches, num_batches, num_samples = 0, 0, 0, 0 with torch.no_grad(): for batch in val_loader: # get batched data input_ids, token_type_ids, start_positions, end_positions = batch input_ids = input_ids.to(device) token_type_ids = token_type_ids.to(device) start_positions = start_positions.to(device) end_positions = end_positions.to(device) # forward pass on validation data start_logits, end_logits = model(input_ids, token_type_ids) # compute loss start_loss = loss_fn(start_logits, start_positions) end_loss = loss_fn(end_logits, end_positions) loss = start_loss + end_loss val_loss += loss.item() num_batches += 1 # compute accuracy pred_start = start_logits.argmax(dim=-1) pred_end = end_logits.argmax(dim=-1) match = (pred_start == start_positions) & (pred_end == end_positions) num_matches += match.sum().item() num_samples += len(start_positions) avg_loss = val_loss / num_batches acc = num_matches / num_samples print(f"Validation {epoch+1}/{num_epochs}: acc {acc:.4f}, avg loss {avg_loss:.4f}") # Save the fine-tuned model torch.save(model.state_dict(), f"bert_model_squad.pth") |
Further Readings
Below are some resources that you may find useful:
- Devlin et al (2018) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Wang et al. (2018) GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
- Rajpurkar et al (2016) SQuAD: 100,000+ Questions for Machine Comprehension of Text
- Google’s BERT implementation
- Hugging Face’s BERT implementation in the transformers library
- Hugging Face’s BERT documentation
Summary
In this article, you learned how to fine-tune a BERT model for GLUE and SQuAD tasks. Specifically, you learned:
- How to build a new model on top of BERT for fine-tuning
- How to run the training loop for fine-tuning
- The GLUE and SQuAD datasets and the tasks they are designed for










 English (US) ·
English (US) ·